This blog attempts to be a collection of how-to examples in the Microsoft software stack - things that may take forever to find out, especially for the beginner. I see it as my way to return something to the Microsoft community in exchange for what I learned from it.
In November 2007, I started my journey into blogging. Little did I know I was taking the first step that would ultimately made me a Microsoft MVP, took me several times to the campus in Redmond, and even put me on the road to HoloLens development. Back then I took the easy and cheap route and opted for Blogger, then an independent company. Unfortunately, the company was later acquired by Google and after that the platform did not get much love anymore. The online editor, at the time great, became more cumbersome to use over time. Then came LiveWriter, part of Microsoft Essentials, and suddenly I could blog in a WYSIWIG Word style editor. This made life so much easier.
But Live Essentials was slowly being phased out, and little by little, Live Writer was also sunsetting. But in the end of 2015 the product was given a new leash on life by being rechristened as "Open Live Writer". This was especially important as Google changed the Blogger API regularly. When it became a Store app, life became even easier: it got updated automatically!
That is... for the time enthusiasts were still willing to maintain it. The repo associated with Open Live Writer has been showing little activity the last year. Also the Blogger platform, having received very little love by Google, has lost a lot of usage, to such an extent that repos for blogging tools simply close down issues asking for Blogger support calling it "a bunch of work for little payback". And this comment is from 2017.
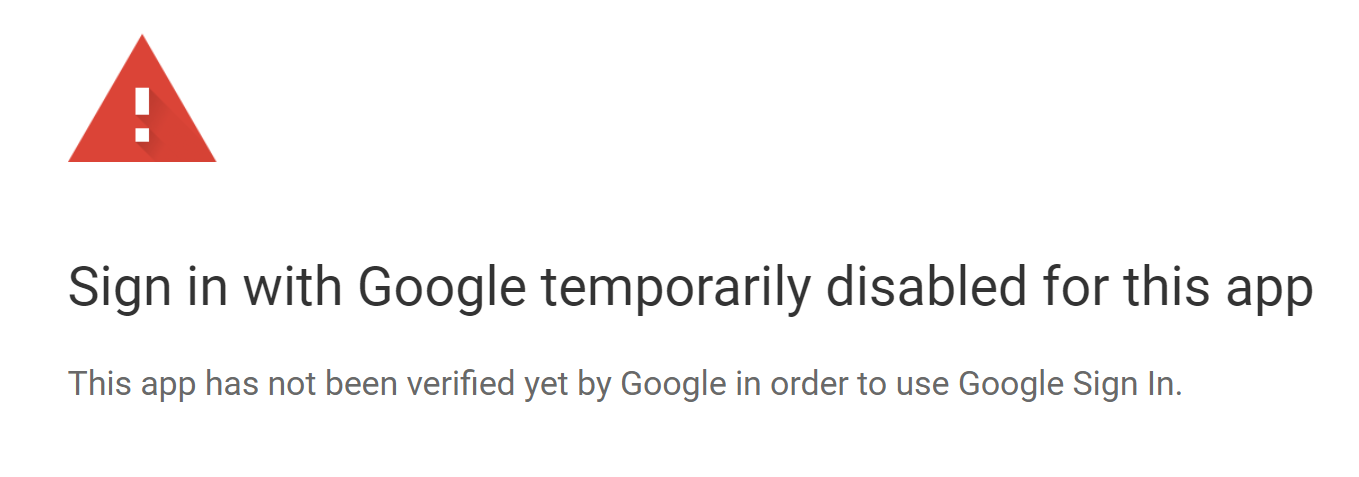
Recently I had my laptop reinstalled, and when I wanted to re-configure Open Live Writer again, I was greeted with this:
At this point, I had enough. After almost 13 years jumping through several hoops to keep this puppy alive, it was time to move on.
DotNetByExample - The Next Generation
And here we are. I have copied over all the content to my new home on the web, using GitHub pages, after consulting with my dear friend Matteo Pagani. This is the provisionary look & feel, there is still a lot I don't like, but at least it's accessible and maintainable for me again. I also wrote a little tool that updates all links to previous blogposts inside the imported pages, and even generates a JavaScript snippet that redirects all links to the migrated articles in the new blog.
So after 13 years, it's time to leave this spot that has been my home on the web for so long. I hope you will all join me on my continuing journey in development!
Select the right sound Spatializer (MS HRTF Spatializer)
And then, since recently, I add NuGet for Unity.
Something is rotten in de state of NuGet
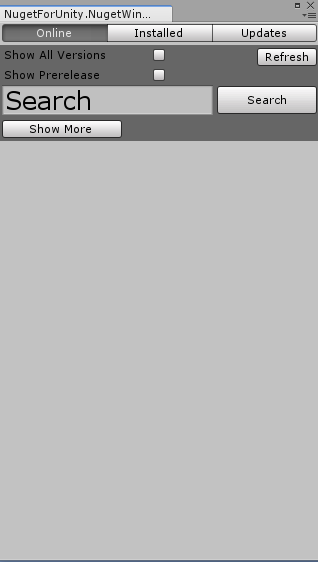
Now this comes a nice UnityPackage that you can download from here. Currently it's at 2.0.1. It works fine in plain Unity projects. It works also fine in UWP build. But if you follow the workflow I show above, it breaks. If you open the NuGet package manager, in stead of the UI you expect, you will see only this:
And you will see these errors in the console:
System.TypeInitializationException: The type initializer for 'NugetForUnity.NugetHelper' threw an exception. ---> System.NullReferenceException: Object reference not set to an instance of an object at NugetForUnity.NugetHelper.LoadNugetConfigFile () [0x0011c] in <b7bde984cef1447da61a3fd28d4789b0>:0 at NugetForUnity.NugetHelper..cctor () [0x001e6] in <b7bde984cef1447da61a3fd28d4789b0>:0
NullReferenceException: Object reference not set to an instance of an object
NugetForUnity.NugetHelper.LoadNugetConfigFile () (at <b7bde984cef1447da61a3fd28d4789b0>:0)
Great. Now what?
The culprit
When you import the the MRTK2, at some point a NuGet.config file is created. This sits in the Assets root and looks like this:
For some reason, NuGet for Unity does not get very happy about that. If you quit Unity, delete NuGet.config and the NuGet.config.meta, start again and open the NuGet package manager again, a new NuGet.config is created that looks like this:
"Unable to retrieve package list from https://pkgs.dev.azure.com/UnityDeveloperTools/MSBuildForUnity/_packaging/UnityDeveloperTools/nuget/v3/index.jsonSearch()?$filter=IsLatestVersion&$orderby=DownloadCount desc&$skip=0&$top=15&searchTerm=''&targetFramework=''&includePrerelease=false
System.Net.WebException: The remote server returned an error: (404) Not Found."
So I actually have no idea why this NuGet.config is created or how. But it definitely needs to go, apparently.
The short version
Before importing NuGet for Unity, check for an existing NuGet.config and NuGet.config.meta and delete those; your NuGet package manager will then work as planned.
No code today, because all I wrote today here boils down to the one sentence above :)
A short one, but one that took me quite some time to find.
If you are using MRTK2 to build a Mixed Reality app to run on Immersive Headsets - or at least an environment where you control the environment using controllers - you can typically 'teleport' forward and backward by pushing the thumbstick forward and backward, and rotate the view by pushing it left and right. Your viewpoint rotates either 90° left or 90° right (and of course you can change the view by rotating your head, but that's not the point). But what if you want to rotate only 45°? Or 22.5°?
I have spent quite some time looking in the MRKT2 config profiles looking for the rotation angle. The reason I could not find it, is because it's not there. At least, not directly. It's in the pointer - the 3D cursor, if you like. Yeah, you read that right.
First, we clone
Starting from a default MRKT2 project, we follow the following steps:
Clone the Toolkit Configuration Profile itself. I used DefaultMixedRealityToolkitConfigurationProfile to start this time.
Under Input, clone the Mixed Reality Input System Profile
Under Pointers, clone the Mixed Reality Input Pointer Profile
Finding the right pointer
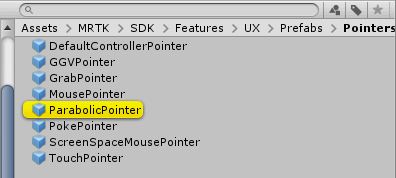
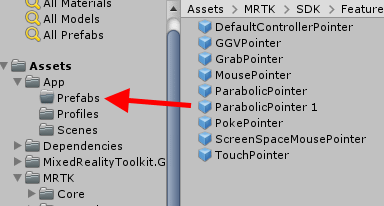
If you expand the Pointers section and then the Pointer Options sections, you will see a whole lot of pointers. The second one is the one we are looking for: ParabolicPointer. It's a prefab.
If you click it, it will open the asset folder Assets/MRTK/SDK/Features/UX/Prefabs/Pointers and highlight the prefab we just selected:
Finding the angle
Press CTRL+D to duplicate the pointer, then drag it the Prefabs folder inside your app:
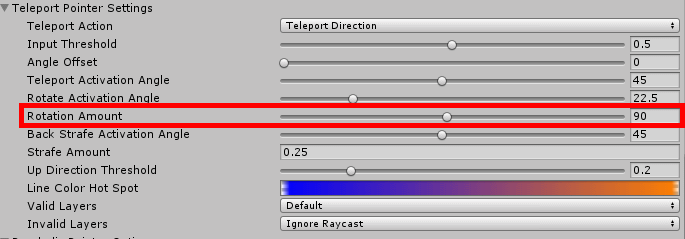
If that folder is not there yet, create it first. Once the prefab is inside the folder, rename it to something recognizable - ParabolicPointer45 for instance. When you are done renaming you have automatically selected the pointer itself. Go over to the inspector, scroll all the way down to the "Parabolic Teleport Pointer" script and there, in the "Teleport Pointer Settings" section, you will finally see where that bloody 90° comes from:
Adapting and applying
So now it's simply a matter of changing the angle to what you want, so for instance 45°. Then you go back to your adapted Mixed Reality Input Pointer Profile and drag your customized point in the right place:
and now your view will only rotate 45° in stead of 90° when you push the thumb stick sideways.
Conclusion
I certainly did not expect this setting being contained in a pointer, as by now I am quite conditioned to look in configuration profiles by now. I was - incorrectly - assuming it would be somewhere in the camera or controller settings. It took me quite some searching and debug breakpoints to find out where things where happening, and I took a few blind alleys before I found the right one. Typically something I blog about so a) I can now easily find back how I did it and b) you now also know where to look for.
Demo project, although it does not do very much, here. When you run it (either from Unity or as an app) in your Immersive Headset, you will see a green 'floor' rotating only 45° when you push the thumbstick stick left or right.
If you - like me - are crazy enough to dutifully update the MRTK2 in your apps whenever a new version arrives, at some point you will notice a kind of puzzling, rather ominous and not very helpful message pop up in your console a couple of times:
"Windows Mixed Reality specific camera code has been moved into Windows Mixed Reality Camera Settings. Please ensure you have this added under your Camera System's Settings Providers, as this deprecated code path may be removed in a future update."
You might have seen this appear earlier, when you upgraded to MRTK 2.3, as you can see in this commit message. Version 2.3 was where it was introduced, in November 2019. The trouble with this message is that the procedure to fix it is not entirely clear - at least, it was not to me. Especially since the first warning originates from the MRTK2 itself (when the MixedRealityCameraSystem is initialized as a service). Also GoogleBinging it yields no result, but I do hope it does so after I post this article. Fortunately it was also originating from my own code, and that was a lot more helpful, as I know what that is about - I wrote it myself, after all.
The culprit was this piece of code:
CoreServices.CameraSystem.IsOpaque
This ends up in Microsoft.MixedReality.Toolkit.CameraSystem.MixedRealityCameraSystem where the IsOpaque property is implemented. That looks for a "IMixedRealityCameraSettingsProvider". That does not help much, but wat does help - in MixedRealityCameraSystem there is a documentation link on top, which at least points you to the right place in the configuration.
So what you need to do is very simple and takes 7 mouse clicks:
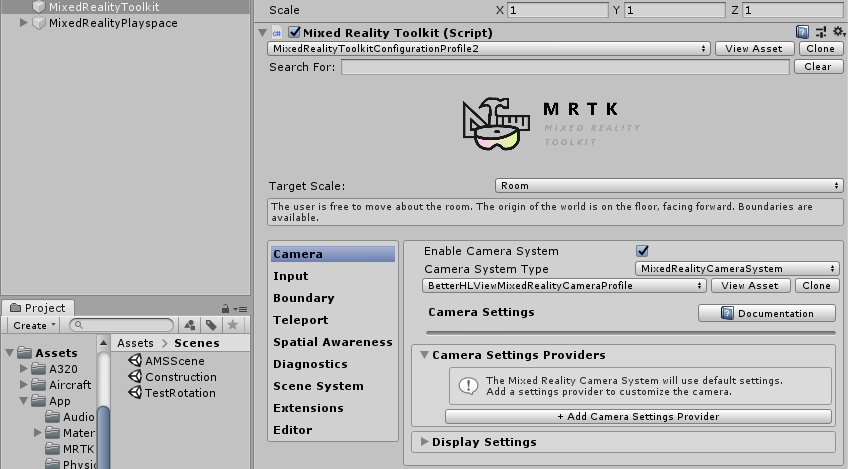
Select the MixedRealityToolkit node in your hierarchy
Select the Camera Tab
Expand the Camera Settings Provider
You will now see this:
Then:
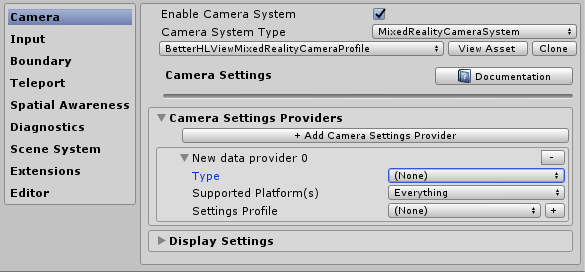
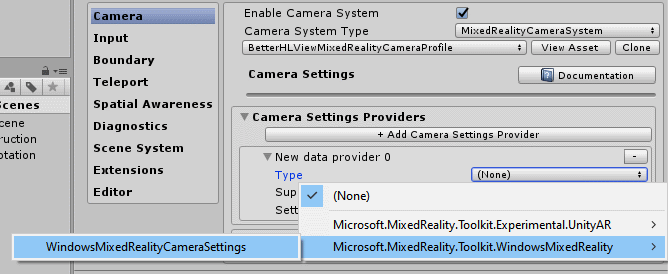
Click the "+ Add Camera Settings Provider" button just above "Display Settings"
Expand the "New data provider 0" section"
For "Type", select Microsoft.MixedReality.Toolkit.WindowsMixedReality/WindowsMixedRealityCameraSettings (this is actually two mouse clicks)
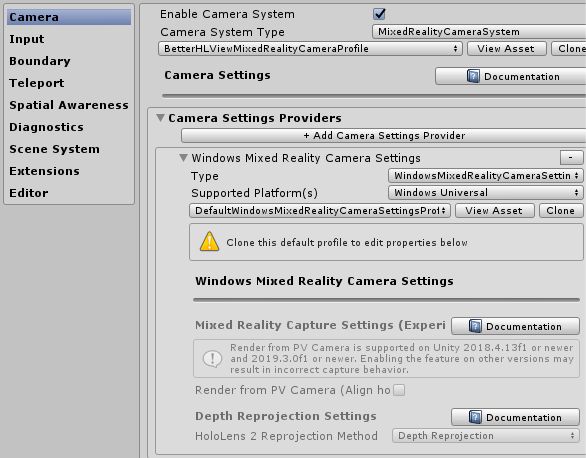
The end result should look like this:
.... and you are done. Unless you need to tweak the settings of the default camera settings profile, in which case you have to do the clone-and-adapt dance. But in any case, no more scary messages about deprecated code that might change in some future release. ;)
I omitted the customary demo project this time, as the point of this post was to show you how to get from A to B, not the end result.
If you are developing an app using the Mixed Reality Toolkit 2 that requires interaction with a Spatial Mesh, the development process can become cumbersome: add code or assets with Unity and Visual Studio, create IL2CPP solution, wait, compile and deploy, wait, check behavior - rinse and repeat. You quickly learn to do as much as possible inside the Unity editor and/or use Holographic Remoting if you want stay productive and make your deadline. But a Spatial Mesh inside the Unity Editor does not exist.
... or does it? ;)
Begun the Clone Wars have again
You guessed it - before we can see anything at all, a lot of cloning and configuring of profiles needs to be happening first.
Clone the Toolkit Configuration Profile itself. I used DefaultHoloLens2CameraProfile this time.
Turn off the diagnostics (as ever).
Enable Spatial Awareness System
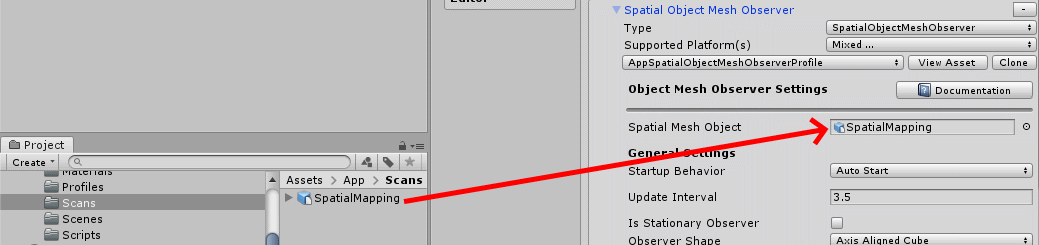
Clone the MixedRealityAwareness profile
Clone the MixedRealityAwarenessMeshObserver profile (the names of these things become more tongue-breaking the deeper you go)
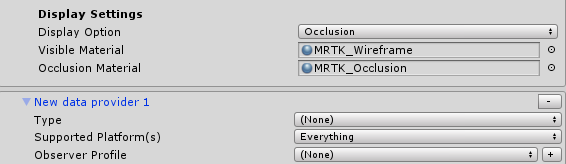
Change the Display option (all the way down) to "Occlusion"
And now the interesting part
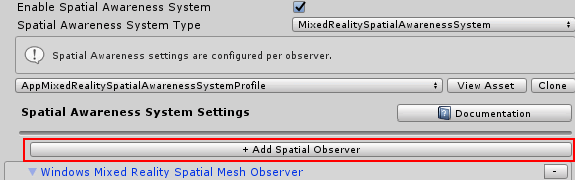
On top of the Spatial Awareness System Settings there's this giant button over the whole length of the UI which is labeled "+ Add Spatial Observer".
If you click that one, it will add a "New data provider 1" at the bottom, below the Display settings we just changed the previous step.
Select "SpatialObjectMeshObserver" for type
And if you hit the play button, lo and behold:
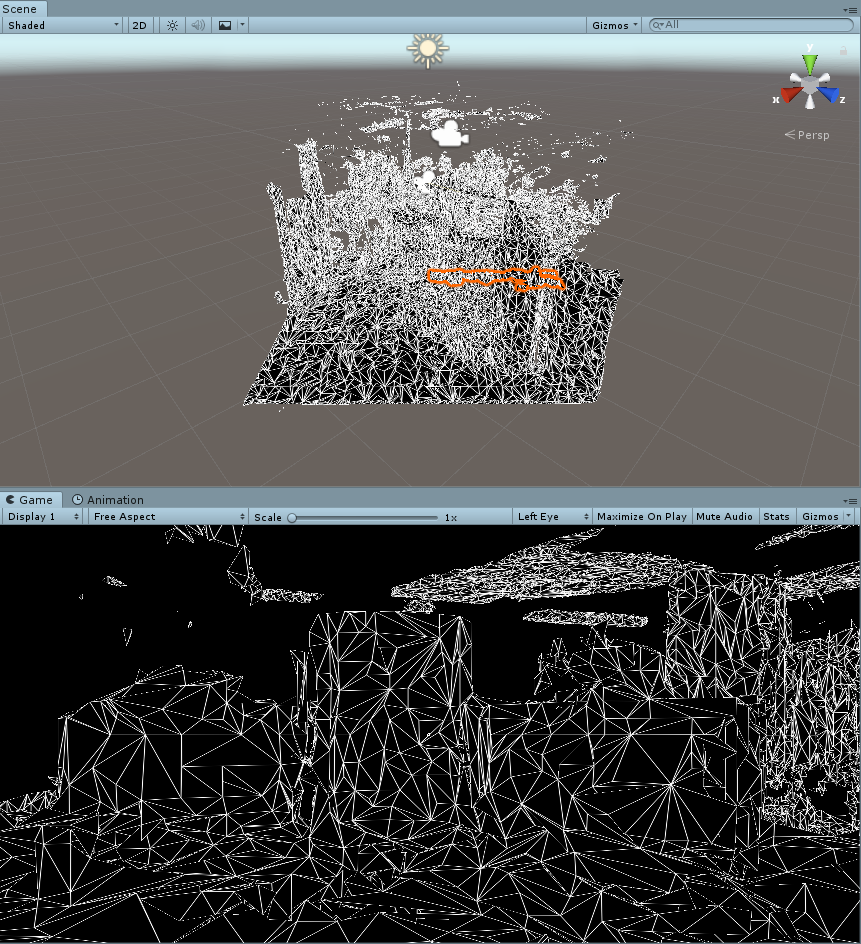
Basically you are now already where you want to be, but although the wireframe material works very well inside a HoloLens, it does not work very well in an editor. At least, that is my opinion.
Making the mesh more usable inside the editor
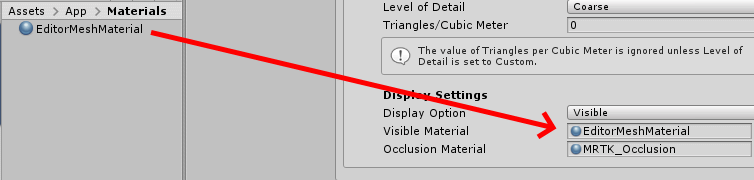
You might have noticed the SpatialObjectMeshObserver comes with a with a profile "DefaultObjectMeshObserverProfile" - I'd almost say of course it does. Anyway, clone that one as well. Then we create a simple material:
Of course using the Mixed Reality Toolkit Standard shader. I only change the color to RGB 115,115,115 which is a kind of battleship grey. You make take any color you fancy, as far as I am concerned. Set that material to the "Visible Material" of the Spatial Mesh Object Observer you just added (not in the material of the "Windows Mixed Reality Spatial Mesh Observer"!)
The result, if you run play mode again, is definitely better IMHO:
Using a mesh of a custom environment
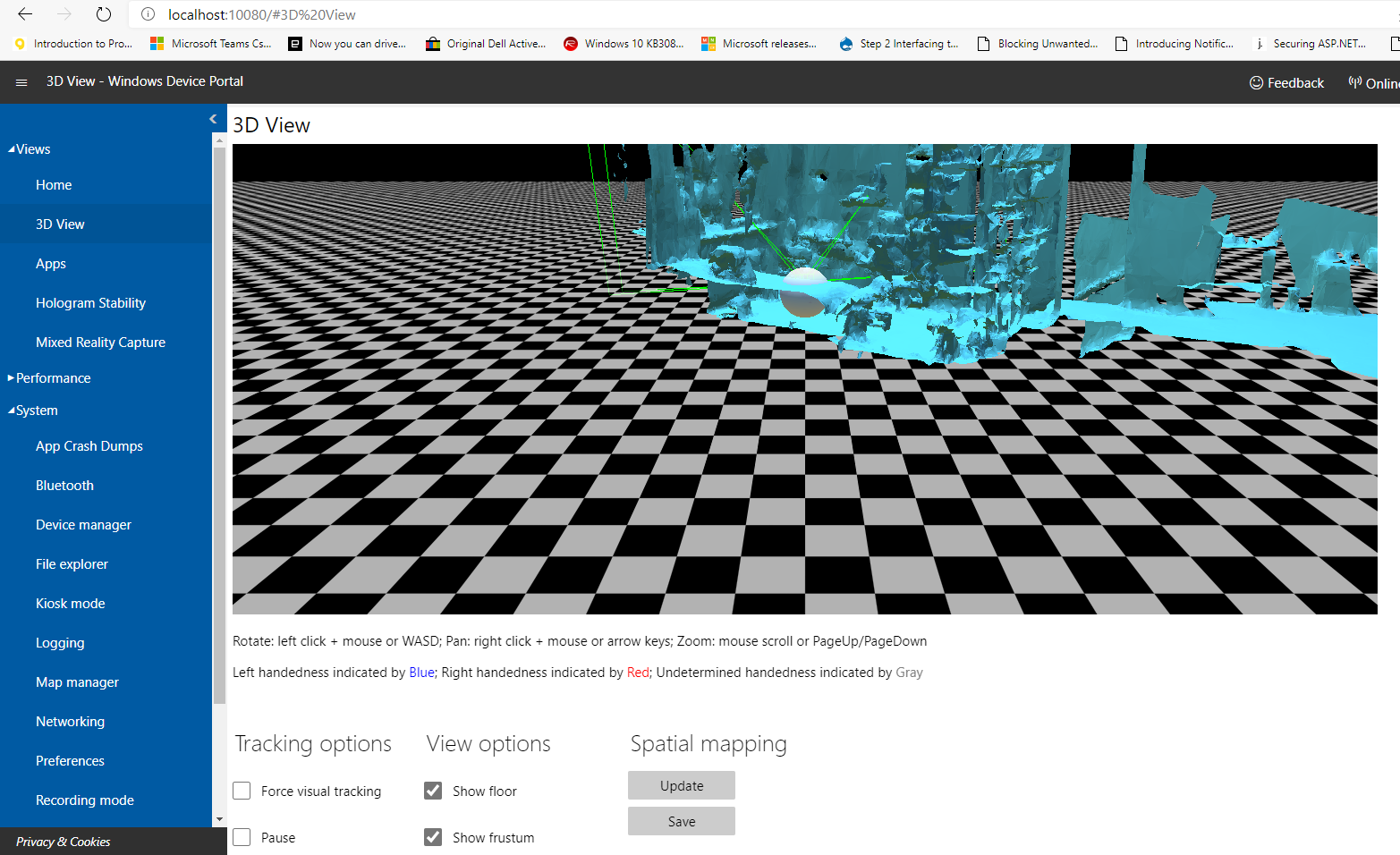
So it's nice to be able to use some sample mesh, but what if you need to the mesh of a real space? No worries, because just like in HoloLens1, the device portal allows you to download a scan of the current (real) space the HoloLens sees:
You can download this space by hitting the save button. This will download a SpatialMapping.obj file. Bring this into your Unity project, then drag it on top of the Spatial Mesh Object observer's "Spatial Mesh Object" property:
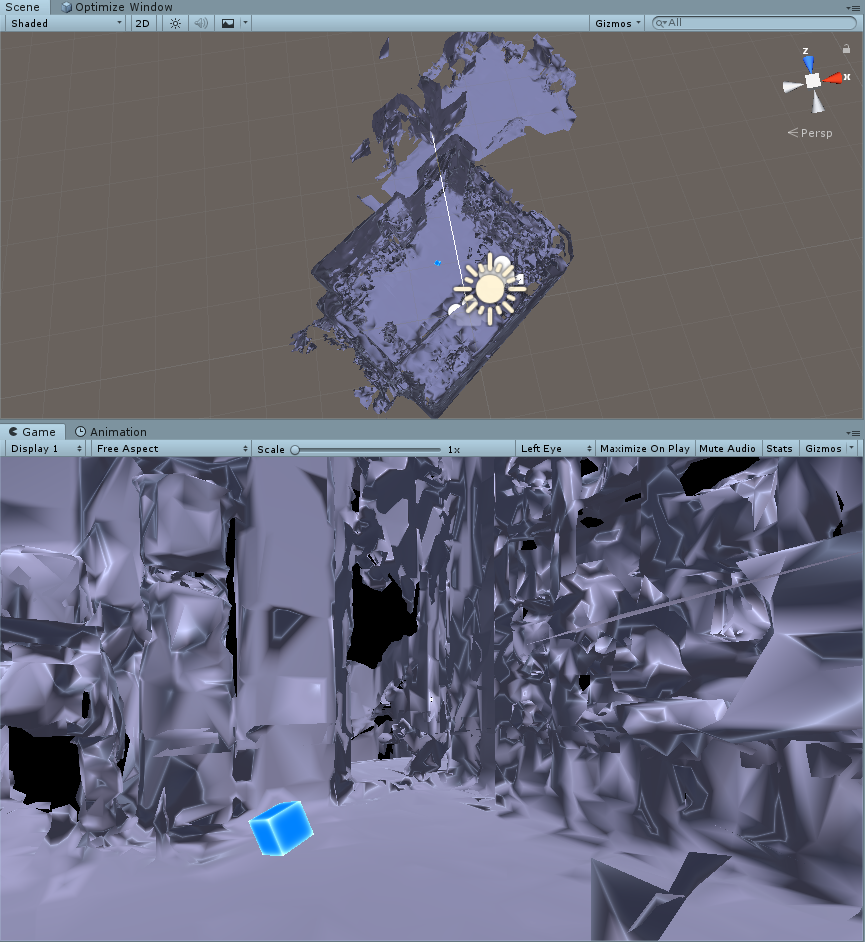
And then, when you hit play mode, you will see the study where I have been hiding in during these worrying times. It has been my domain for working for the past 2.5 months for working and blogging, as well as following BUILD and the Mixed Reality Dev Days. If you download the demo project, it will also include a cube that moves forward, to show objects actually bounce off the fake spatial mesh, just like a real spatial mesh.
Note: if you compile and deploy this project to a HoloLens (either 1 or 2) you won't see this 'fake mesh' at all. It only appears in the editor. Which is exactly what we want. It's for development purposes only.
Conclusion
Using this little technique you can develop for interacting with the Spatial Mesh while staying inside the Unity editor. You will need less access to a physical HoloLens 2 device, but more importantly speed up development this way. The demo project is, al always, on GitHub
As I announced in this tweet that you might remember from February the HoloLens 2 version of my app Walk the World sports two hand palm menus - a primary menu, often used command menu that is attached to your left hand that you operate with your right hand, and a secondary less-used settings menu that is attached to your right hand - and that you operate with your left. Lorenzo Barbieri of Microsoft Italy, a.k.a. 'Evil Scientist' ;) did the brilliant suggestion I should accommodate left-handed usage as well. And so I did - I added a button to the settings menu that actually swaps the 'handedness' of the menus. This means: if you select 'left handed operation' the main menu is operated by your left hand, and the secondary settings menu by your right.
A little video makes this perhaps more clear:
This blog explains how I made this work. I basically extracted the minimal code from my app and made it into a mini app that doesn't do more than make the menu swappable - both by pressing a toggle button and by a speech command. I will discuss the main points, but not everything in detail - but as always you can download a full sample project and see how it's working in the context of a complete running app.
This sample uses a few classes of my MRTKExtensions library of useful scripts.
Configuring the Toolkit
I won't cover this in much detail, but the following items need to be cloned and partially adapted:
The Toolkit Configuration Profile itself (I usually start with DefaultMixedRealityToolkitConfigurationProfile). Turn off the diagnostics (as ever)
The Input System Profile
The SpeechCommandsProfile
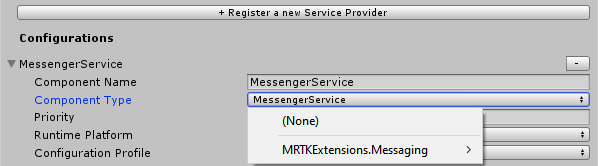
The RegisteredServiceProviderProfile
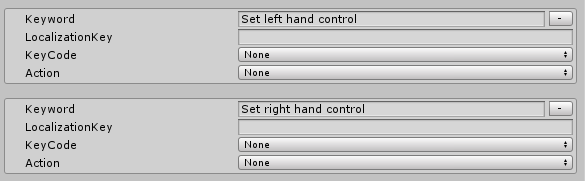
Regarding the SpeechCommandsProfile: add two speech commands:
Set left hand control
Set right hand control
In the RegisteredServiceProviderProfile, register the Messenger Service that is in MRKTExtension.Messaging. If you have been following this blog, you will be familiar with this beast. I introduced this service as a Singleton behavior back in 2017 and converted it to a service when the MRTK2 arrived.
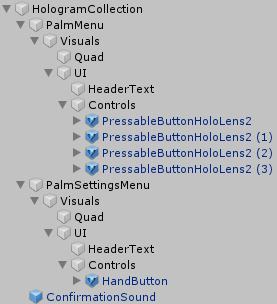
Menu structure
I already explained how to make a hand menu last November, and in my previous blog post I explained how you should arrange objects that should be laid out in a grid (like buttons). The important things to remember are:
All objects that are part of a hand menu should be in a child object of the main menu object. In the sample project, this child object is called "Visuals" inside each menu.
All objects that should be easily arrangeable in a grid, should be in a separate child object within the UI itself. I always all this child object "UI", and this is where you put a GridObjectCollection behaviour on.
Consistent naming makes a structure all the more recognizable I feel.
Menu configuration
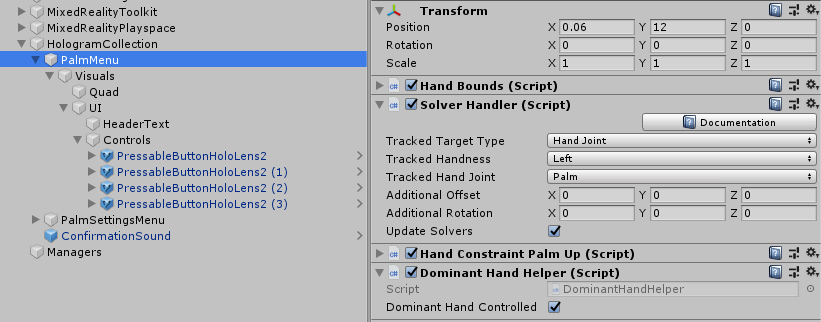
The main palm menu has, of course, a Solver Handler and a Hand Constraint Palm Up behaviour. The tracked hand is set to the left.
The tricky thing is always to remember - the main menu is going to be operated by the dominant hand. For most people the dominant hand is right - so the hand to be tracked for the dominant menu is the left hand, because that leaves the right hand free to actually operate controls on that menu. For left hand control the main menu has to be set to track the right hand. This keeps confusing me every time.
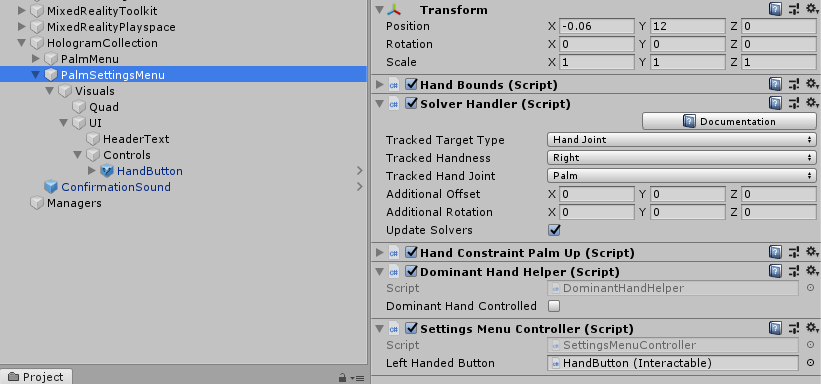
On the palm. It won't surprise you to see the Settings menu look like this:
With the Solver's TrackedHandedness set to Right. But here you also see the star of this little show: the DominantHandController, with the DominantHandController set to off - since I always have the settings menu operated by the non dominant hand, whatever that might be.
DominantHandController
This is actually a very simple script, that responds to messages sent from either a button or from speech commands:
SetSolverHandedness determines what the handedness of the solver should be set to - depending on whether this menu is set to be controlled by the dominant hand or not, and whether or not left handed control is wanted. That's an XOR yes, you don't see that very often. But write out a truth table for those two parameters and that's where you will end up with. This little bit of code is what actually does the swapping of the menus from right to left and vice versa.
It also returns a value to see if the value has actually changed. This is because if the command is started from a speech command we want, like any good Mixed Reality developer, give some kind of audible cue the command has been understood and processed. After all, we can say a speech command any time we want, and if the user does not have a palm up, he or she won't see hand menu flipping from one hand to the other. So only if the command comes from a speech command, and actual change has occurred, we need to give some kind of audible confirmation. I also added this confirmation only to be given by the dominant hand controller - otherwise we get a double confirmation sound. After all, there are two of these behaviours active - one for each menu.
Supporting act: SettingsMenuController
Of course, something still needs to respond to the Toggle Button being pressed. This is done by the this little behaviour:
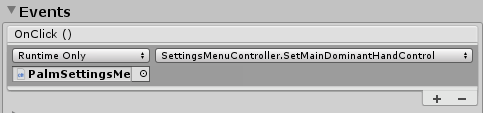
The SetMainDominantHandControl is called from the OnClick event in the Interactable behaviour on the toggle button:
and then simply fires off the message based upon the toggle status of the button. Note that there's a slight delay, this has two reasons:
Make sure the sound the button plays actually has time to play
Make sure the button's IsToggled is actually set to the right value before we fire off the message.
Yeah, I know, it's dicey but that's how it apparently needs to work. Also note this little script not only fires off HandControlMessage but also listens to it. After all, if someone changes the handedness by speech commands, we want to see the button's toggle status reflect the actual status change.
Some bits and pieces
The final piece of code - that I only mention for the sake of completeness - is SpeechCommandProcessor :
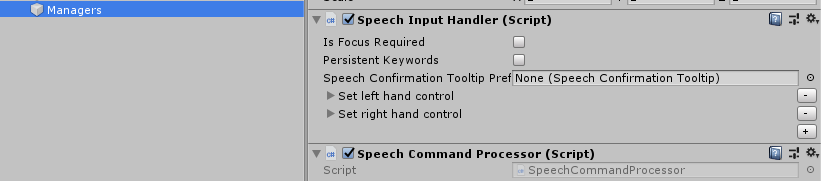
It sits together with a SpeechInputHandler in Managers:
Just don't forget to turn off the "Is Focus Required" checkbox as these are global speech commands. Itned to forget this, and that makes for an amusing few minutes of shouting to your HoloLens without it having any effect, before the penny drops.
Conclusion
You might have noticed I don't let the menu's appear on your hand anymore but next to your hand. This comes from the design guidelines on hand menu's on the official MRKT2 documentation, and although I can have a pretty strong opinion about things, I do tend to take some advice occasionally ;) - especially when it's about usability and ergonomics. Which is exactly why I made this left-to-right swappability in the first place. I hope this little blog post will give people some tools to add a little bit to inclusivity for HoloLens 2 applications.
This is simple, short but I have to blog it because I discovered this, forgot about it, then discovered it again. So if anything this blog is for informing you as well al to make sure I keep remembering this myself.
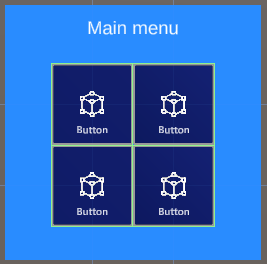
If you have done any UI design for Mixed Reality or HoloLens, you have been in this situation. The initial customer requirement ask for a simple 4 button menu. So you make a neat menu in a 2x2 grid, and are very satisfied with yourself. The next day suddenly you find out you need two more buttons. So - do you make a 2x3 or a 3x2 menu? You decide on the latter, painstakingly arrange them in a nice grid again.
The day after that, there's 2 more buttons. The day after that, 3 more. And the next day... you discover GridObjectCollection. Or in my case, rediscover it.
Simple automatic spacing
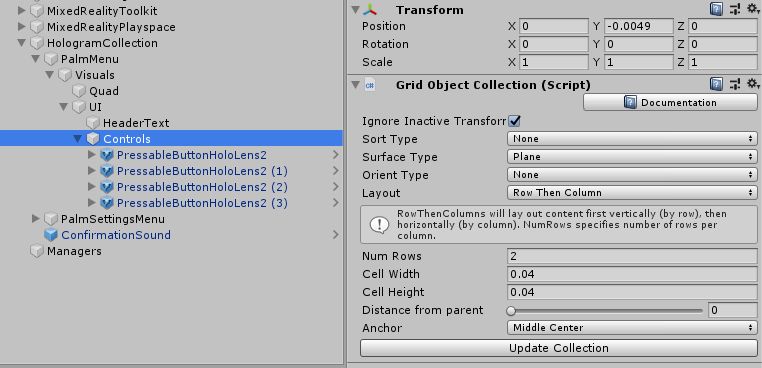
So here is our simple 2x2 menu in the hierarchy. This is a hand menu. It has has a more complex structure than you would imagine, but this is because I am lazy and want an easily adaptable menu that can be organized by GribObjectCollection
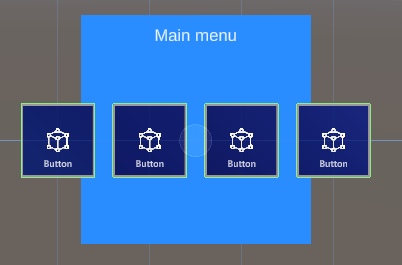
The point is, everything that needs to be easily organizable by GridObjectCollection, needs to be a child of the object that has the actual GridObjectCollection behaviour attached. In my case that's the empty gameobject "Controls". Now Suppose I want this menu not to be 2x2 but 1 x 4. I simply need to change "Num Rows" into 1, press the "Update Collection" button and presto:
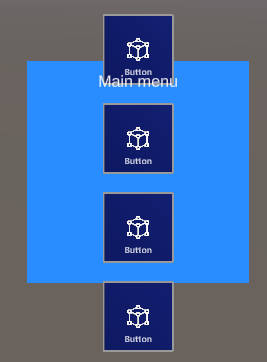
Of course, you will need to update the background plate and move the header text, but that's a lot less work than changing the layout of these buttons. Another example: change the default setting for "Layout" from "Row Then Column" to "Colum then Row", set "Num Rows" to 1 again (for it will flip to 4 when you change the Layout dropdown) and press "Update Collection" again:
You can also change how the button spacing by changing Cell Height and Cell Width. For instance, if I have a 4x4 grid and a cell distance width of 0.032 they are perfectly aligned together without any space in between (not recommended for real live scenario's where you are supposed to press these buttons - a mistake is easily made this way)
You can also do fun things like having then sorted out by name, child order, and both reversed. Or have them spaced out on not only a flat surface, but on a Cylinder, Sphere or a Radial area.
Note: the UpdateCollection can also be accessed by code, so you can actually use this script runtime as well. I mainly use it for static layouts.
Conclusion
Don't waste time in manual spacing, use this very handy tool in the editor to make a nice an evenly spaced button menu - or for whatever you need to have laid out.
Note:
Make it yourself easy by putting any parts of an UI that should be in a grid in a separate empty game object and put the GridObjectCollection control on that, and place the other parts outside that, so they won't interfere with the layout process.
You can use this behaviour with any type of game object, not only buttons of course
More details about GridObjectCollection can be found on the documentation page on GitHub. This also handles related behaviours like ScatterObjectCollection and TileObjectCollection.
No code so no project, although in the next blog post this technique will be applied 'in real life', so to speak.



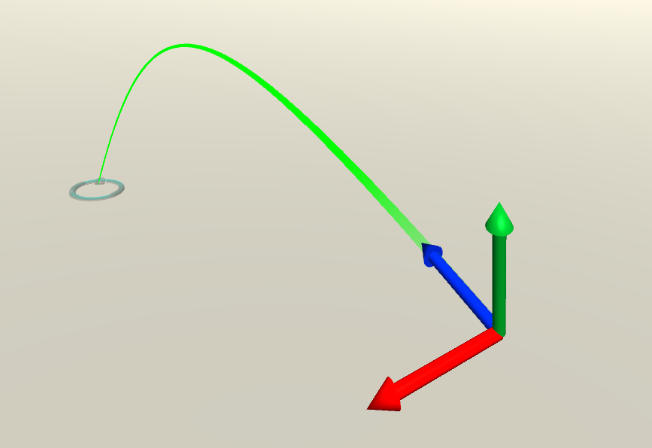 A short one, but one that took me quite some time to find.
A short one, but one that took me quite some time to find.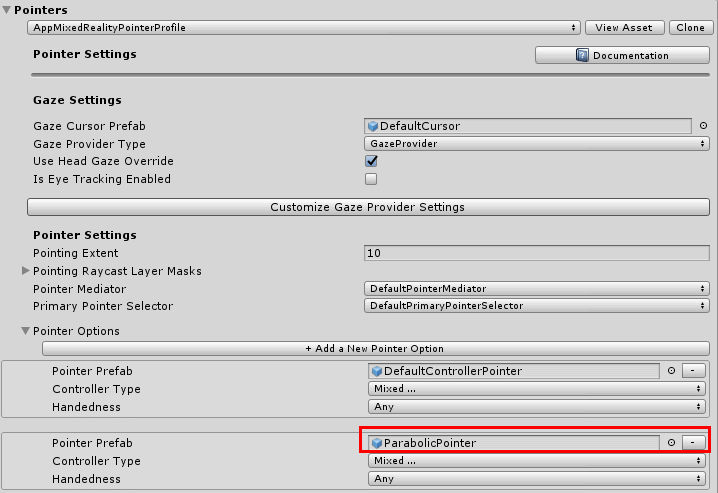

 If you are developing an app using the
If you are developing an app using the 



 Menu structure
Menu structure